ARM64下Indirect Result Location摸索
之前学习汇编的时候,大概了解了一些ARM64下寄存器的用途,比如x0 - x7作为函数传递使用。同时,x0也可以作为函数返回值时候的寄存器。
但是,今天在研究一些跟返回结构体相关的时候,发现返回值并不是放在X0寄存器中。上网搜索了一下资料,发现在ARM64下,当一个Callee函数返回的内容大于16bytes的时候,该内容会被存到一个内存地址当中,然后这个内存地址的值会存入寄存器x8。后续Caller函数在使用该返回值的时候,会从X8寄存器中取出内存地址,并从内存地址取出内容的值
是不是有点绕,还是让我们来看个例子吧。
原理
首先我根据大于16 bytes的要求定义了如下结构体:
typedef struct {
int64_t i;
int64_t j;
int64_t k;
} MYStruct;
在ARM64下,该结构体默认按4 bytes对齐,每个int64占用8 bytes,因此结构体大小24 bytes
我们定义如下函数,用于返回一个该结构体:
- (MYStruct)testIndirectResultLocation:(int64_t)i1 second:(int64_t)i2 th:(int64_t)i3
{
MYStruct s;
s.i = i1;
s.j = i2;
s.k = i3;
return s;
}
这个函数很简单,传入三个值。然后构造个局部变量MYStruct s,将其对应的成员变量按照刚刚的传入参数赋值,最后返回该结构体。
该函数调用在未优化的前提下的汇编结果如下:
IndirectResultLocation`-[ViewController testIndirectResultLocation:second:th:]:
// 预留空间
<+0>: sub sp, sp, #0x40 ; =0x40
// 存参
<+4>: str x0, [sp, #0x38]
<+8>: str x1, [sp, #0x30]
<+12>: str x2, [sp, #0x28]
<+16>: str x3, [sp, #0x20]
<+20>: str x4, [sp, #0x18]
// 赋值
-> <+24>: ldr x0, [sp, #0x28]
<+28>: str x0, [sp]
<+32>: ldr x0, [sp, #0x20]
<+36>: str x0, [sp, #0x8]
<+40>: ldr x0, [sp, #0x18]
<+44>: str x0, [sp, #0x10]
// 将结构体存到x8寄存器的值代表的地址去
<+48>: ldr x0, [sp]
<+52>: str x0, [x8]
<+56>: ldr x0, [sp, #0x8]
<+60>: str x0, [x8, #0x8]
<+64>: ldr x0, [sp, #0x10]
<+68>: str x0, [x8, #0x10]
// 释放空间
<+72>: add sp, sp, #0x40 ; =0x40
<+76>: ret
第一行:SP即Stack Pointer,向下减0x40(64 bytes)的大小,预先分配出函数需要用的栈空间。为什么要预留这么多的大小呢?首先按照Objective-C的函数调用规定,前两个参数必须是self和selector,也即会使用到寄存器X0和X1。然后该函数有三个形参,使用了X2-X4的寄存器。
上述这五个,大小占用了self(8 bytes) + selector(8 bytes) + 三个参数(24 bytes) = 40 bytes。那么还有24 bytes去干嘛了呢?
别忘了,我们在函数中可以声明了一个局部变量MYStruct s,该结构体大小是24 bytes。而在函数调用中使用到的变量,基本上都在栈区中开辟对应的空间进行暂存。
后续第二行到第六行非常简单易懂,就是把上述5个参数存到实际的栈区中去使用。按照这个存法以后,内存布局如下(注意高地址在上,低地址在下,ARM下的栈是向下增长):

将参数都存入到栈以后,我们就要对结构体进行赋值了,这些操作在第七行到第十二行之间。
将1赋值给[SP],2赋值给[SP + #0x8],3赋值给[SP + #0x10]。如果不理解啥意思的话,可以看下我自己转化的伪代码:
void *address = &s;
*(int64_t *)(address) = 1;
*(int64_t *)(address + 8) = 2;
*(int64_t *)(address + 16) = 3;
赋值完以后,我们可以通过内存分布看下数据是否正确:

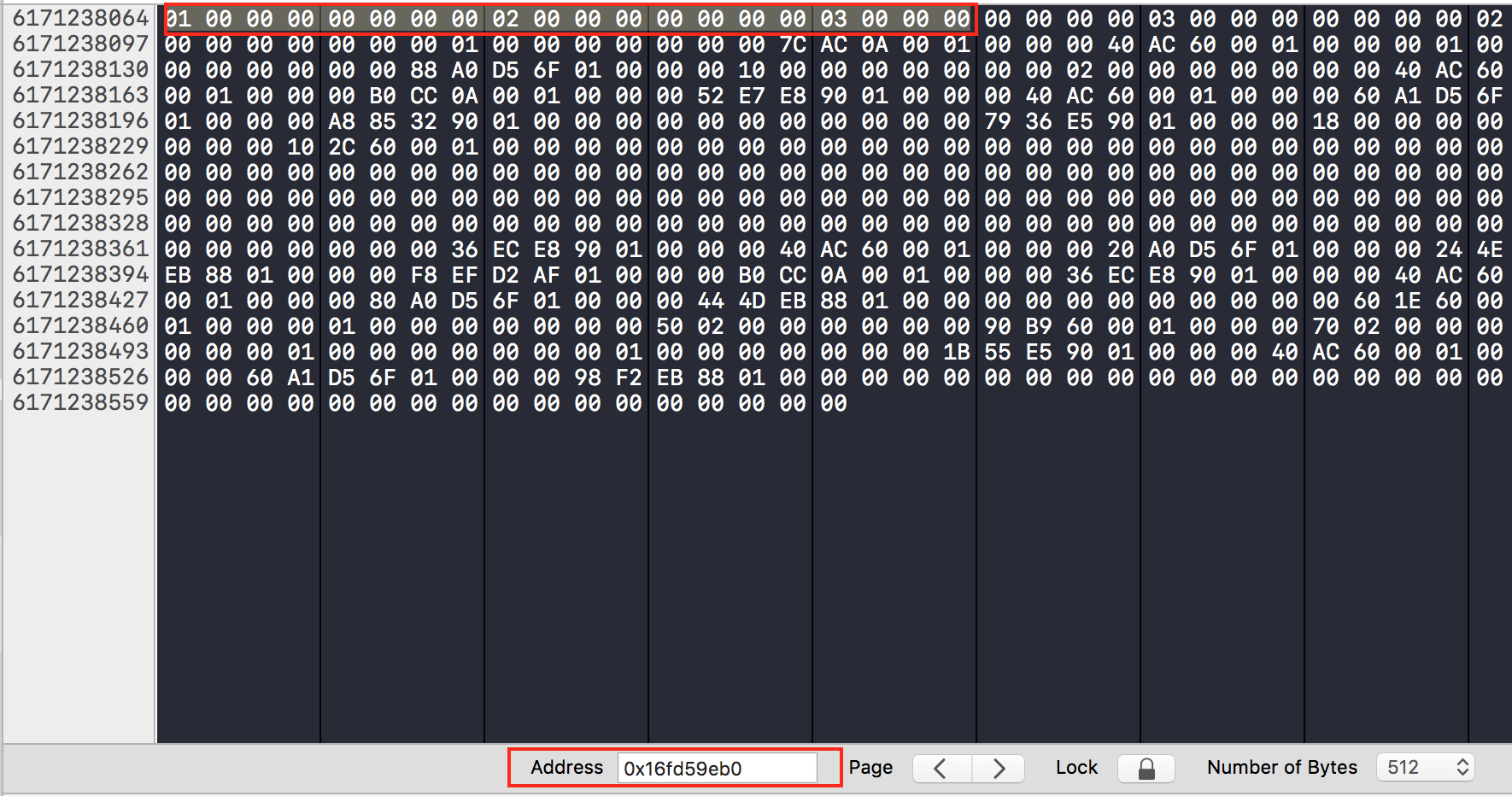
当赋值完成后,就要进行结构体的返回了。这里不是简单的mov x0, sp之类的操作,而是一串和X8寄存器相关操作。
其实原理差不多,转化成伪代码的话,基本上是这样:
void *toSaveAddress = [x8];
void *valueNowAddress = [sp];
*(int64_t *)(toSaveAddress) = *valueNowAddress;
*(int64_t *)(toSaveAddress + 8) = *(valueNowAddress + 8);
*(int64_t *)(toSaveAddress + 16) = *(valueNowAddress + 16);
操作完成后,释放空间即可。
补充
其实ARM64在汇编层面实现的这么复杂, 我们在编程层面只要按照如下方式理解即可:
some_struct foo(int arg1, int arg2);
some_struct s = foo(1, 2);
会被编译成:
some_struct* foo(some_struct* ret_val, int arg1, int arg2);
some_struct s;
foo(&s, 1, 2);
后续
从本文中我们不难看出,ARM64针对不同大小的返回值都有着对应的Calling Convention。下次我准备来摸索下,处于8 bytes - 16 bytes之间的返回值究竟是怎么处理的。