XNU之二和之三两篇由于涉及的量过大,就不发了,当然本文我也删除了一定的内容,哈哈哈。
欢迎加入我们手淘/天猫的架构组来内网阅读
提起iOS的内存管理,大多数人第一反应想到的都是引用计数、ARC、AutoreleasePool之类的词眼。但是事实上,这只是iOS内存管理的冰山一角,今天就让我们来探究水面之下的内存管理。
虚拟内存的限制
我之所以想研究这个议题,主要还是之前有个UC同事问了我一个问题:
“现在绝大多数都是ARM64的设备,即64位寻址空间,而且iOS上的通过malloc申请的内存只是虚拟内存,还不是真正物理内存,为什么分配了两三G就会失败了。”
按照他的想法,我在我的iPhone上测试了如下代码:
void *buffer = malloc(2000 * 1024 * 1024);
果不其然,报出了如下错误:
malloc: *** mach_vm_map(size=2097152000) failed (error code=3)
*** error: can't allocate region
次奥,我xxxxx分配一个2G虚拟内存就懵逼?
还是赶紧翻翻看源码,由于我分配的是一个超大的内存,所以按照nano_zone和scalable_zone的设计理念,
- 小于256byte的走
nano_zone进行分配。 - 剩下的我记不得了
赶紧翻翻scalable_zone看看源码,如下所示:
void * szone_malloc_should_clear(szone_t *szone, size_t size, boolean_t cleared_requested)
{
void *ptr;
msize_t msize;
if (size <= SMALL_THRESHOLD) {
// tiny size: <1024 bytes (64-bit), <512 bytes (32-bit)
// think tiny
msize = TINY_MSIZE_FOR_BYTES(size + TINY_QUANTUM - 1);
if (!msize) {
msize = 1;
}
ptr = tiny_malloc_should_clear(szone, msize, cleared_requested);
} else if (size <= szone->large_threshold) {
// small size: <15k (<1GB machines), <127k (>1GB machines)
// think small
msize = SMALL_MSIZE_FOR_BYTES(size + SMALL_QUANTUM - 1);
if (!msize) {
msize = 1;
}
ptr = small_malloc_should_clear(szone, msize, cleared_requested);
} else {
// large: all other allocations
size_t num_kernel_pages = round_page_quanta(size) >> vm_page_quanta_shift;
if (num_kernel_pages == 0) { /* Overflowed */
ptr = 0;
} else {
ptr = large_malloc(szone, num_kernel_pages, 0, cleared_requested);
}
}
#if DEBUG_MALLOC
if (LOG(szone, ptr)) {
malloc_printf("szone_malloc returned %p\n", ptr);
}
#endif
/*
* If requested, scribble on allocated memory.
*/
if ((szone->debug_flags & MALLOC_DO_SCRIBBLE) && ptr && !cleared_requested && size) {
memset(ptr, SCRIBBLE_BYTE, szone_size(szone, ptr));
}
return ptr;
}
- 小于1k的走
tiny_malloc - 小于15k或者127k的走
small_malloc(视具体不同的设备内存上限不同) - 剩下的走
large_malloc。
OK,由于我们分配的非常大,我们可以确定我们的逻辑是落入large_malloc中。需要特别注意的是:large_malloc分配内存的基本单位是一页大小,而对于其他的几种分配方式,则不是必须按照页大小进行分配。
由于large_malloc这个函数本身并没有特殊需要注意的地方,我们直接关注其真正分配内存的地方,即allocate_pages,如下所示:
vm_addr = vm_page_quanta_size;
kr = mach_vm_map(mach_task_self(), &vm_addr, allocation_size, allocation_mask, alloc_flags, MEMORY_OBJECT_NULL, 0, FALSE,
VM_PROT_DEFAULT, VM_PROT_ALL, VM_INHERIT_DEFAULT);
if (kr) {
szone_error(szone, 0, "can't allocate region", NULL, "*** mach_vm_map(size=%lu) failed (error code=%d)\n", size, kr);
return NULL;
}
addr = (uintptr_t)vm_addr;
从上我们不难看出,如果分配失败,就是提示报错。而mach_vm_map则是整个内存的分配核心。
可能你一开始看到这个mach_vm_map会比较懵逼,可以先看下我下面这张图:
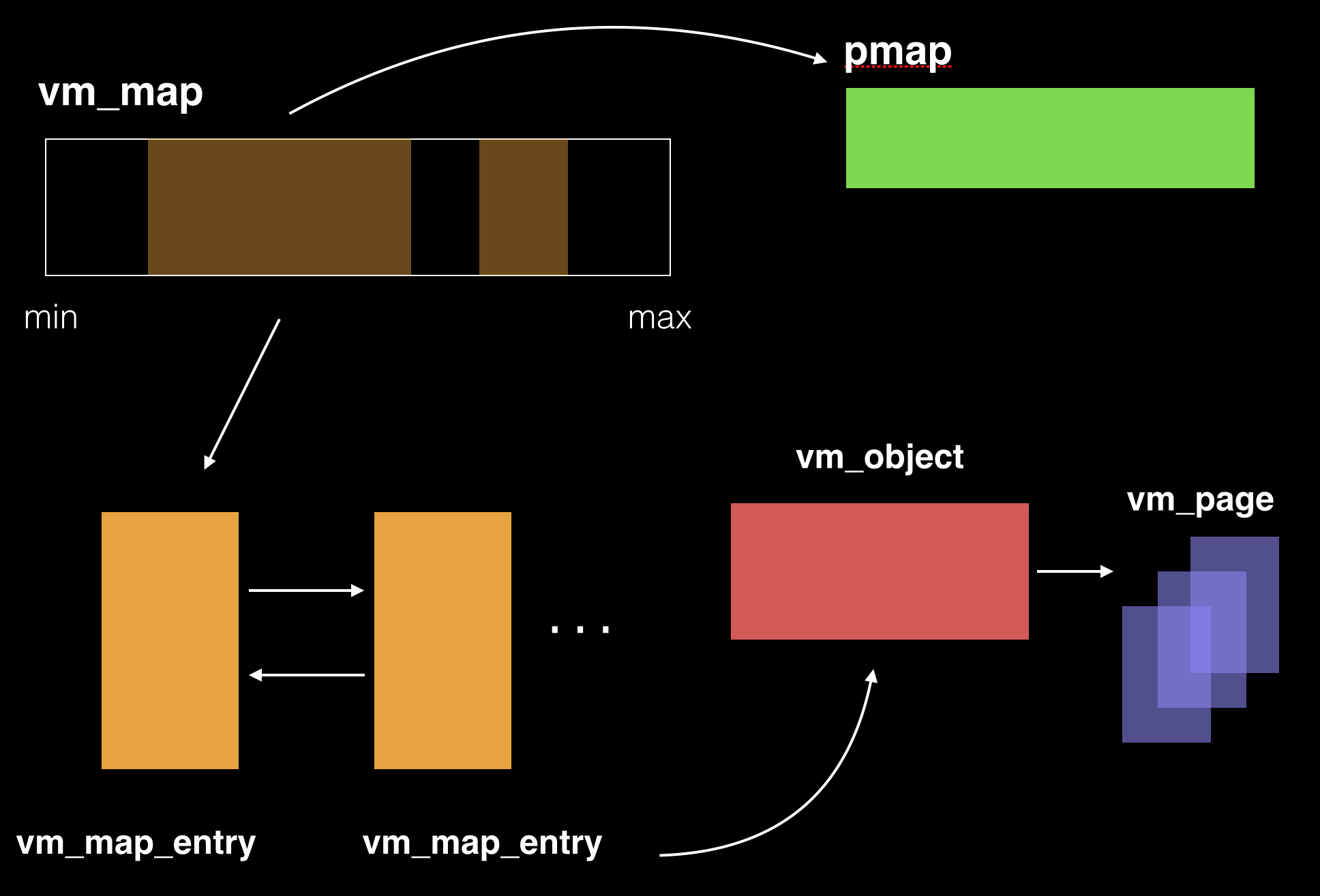
OK,是不是有冒出很多名词。没关系,你其实只要记住两点:vm_map代表就是一个进程运行时候涉及的虚拟内存,pmap代表的就是和具体硬件架构相关的物理内存。(这里我们暂时先不考虑submap这种情况)。
好,vm_map本身是进程(或者从Mach内核的角度看是task的地址分布图)。这个地址分布图维护着一个双向列表,列表的每一项都是vm_entry_t,代表着虚拟地址上连续的一个范围。而pmap这个结构体代表了个硬件相关的内存转换:即利用pmap这个结构体来描述抽象的物理地址访问和使用。
进程(任务)的创建
在继续深入我们的话题之前,我们还需要具备一个额外的知识,就是iOS上的进程创建和加载执行Mach-O过程。
类UNIX系统本质上是没法无缘无故创建出一个全新的进程的,基本上必须要通过fork的形式来创建。(这块不太熟悉,有错请指正)。
在XNU的实现里,不论用户态调用posix相关API还是别的API,落入到内核里面都走的是fork_create_child函数来创建属于Mach内核的任务(task)。其实现如下:
thread_t
fork_create_child(task_t parent_task, coalition_t *parent_coalitions, proc_t child_proc, int inherit_memory, int is64bit, int in_exec)
{
thread_t child_thread = NULL;
task_t child_task;
kern_return_t result;
/* Create a new task for the child process */
result = task_create_internal(parent_task,
parent_coalitions,
inherit_memory,
is64bit,
TF_LRETURNWAIT | TF_LRETURNWAITER, /* All created threads will wait in task_wait_to_return */
in_exec ? TPF_EXEC_COPY : TPF_NONE, /* Mark the task exec copy if in execve */
&child_task);
if (result != KERN_SUCCESS) {
printf("%s: task_create_internal failed. Code: %d\n",
__func__, result);
goto bad;
}
if (!in_exec) {
/*
* Set the child process task to the new task if not in exec,
* will set the task for exec case in proc_exec_switch_task after image activation.
*/
// 注意点:
child_proc->task = child_task;
}
- 这个函数本身实现并没什么出彩的,我们唯一要注意的就是Mach内核里面没有进程的概念,只有任务,进程是属于BSD之上的抽象。它们之间的联系就是通过指针建立,
child_proc->task = child_task。
fork出来的进程更像是一个空壳,我们需要利用这个进程壳去执行可执行文件变成我们通常意义上理解的程序进程。
从XNU上来看,可执行的文件种类如下:
{ exec_mach_imgact, "Mach-o Binary" },
{ exec_fat_imgact, "Fat Binary" },
{ exec_shell_imgact, "Interpreter Script" }
这里咱们先只看最常用的Mach-O文件:
exec_mach_imgact(struct image_params *imgp)
{
... 省略无数
if ((mach_header->magic == MH_CIGAM) ||
(mach_header->magic == MH_CIGAM_64)) {
error = EBADARCH;
goto bad;
}
if ((mach_header->magic != MH_MAGIC) &&
(mach_header->magic != MH_MAGIC_64)) {
error = -1;
goto bad;
}
if (mach_header->filetype != MH_EXECUTE) {
error = -1;
goto bad;
}
if (imgp->ip_origcputype != 0) {
/* Fat header previously had an idea about this thin file */
if (imgp->ip_origcputype != mach_header->cputype ||
imgp->ip_origcpusubtype != mach_header->cpusubtype) {
error = EBADARCH;
goto bad;
}
} else {
imgp->ip_origcputype = mach_header->cputype;
imgp->ip_origcpusubtype = mach_header->cpusubtype;
}
task = current_task();
thread = current_thread();
uthread = get_bsdthread_info(thread);
if ((mach_header->cputype & CPU_ARCH_ABI64) == CPU_ARCH_ABI64)
imgp->ip_flags |= IMGPF_IS_64BIT;
/* If posix_spawn binprefs exist, respect those prefs. */
psa = (struct _posix_spawnattr *) imgp->ip_px_sa;
if (psa != NULL && psa->psa_binprefs[0] != 0) {
int pr = 0;
for (pr = 0; pr < NBINPREFS; pr++) {
cpu_type_t pref = psa->psa_binprefs[pr];
if (pref == 0) {
/* No suitable arch in the pref list */
error = EBADARCH;
goto bad;
}
if (pref == CPU_TYPE_ANY) {
/* Jump to regular grading */
goto grade;
}
if (pref == imgp->ip_origcputype) {
/* We have a match! */
goto grade;
}
}
error = EBADARCH;
goto bad;
}
grade:
if (!grade_binary(imgp->ip_origcputype, imgp->ip_origcpusubtype & ~CPU_SUBTYPE_MASK)) {
error = EBADARCH;
goto bad;
}
/* Copy in arguments/environment from the old process */
error = exec_extract_strings(imgp);
if (error)
goto bad;
AUDIT_ARG(argv, imgp->ip_startargv, imgp->ip_argc,
imgp->ip_endargv - imgp->ip_startargv);
AUDIT_ARG(envv, imgp->ip_endargv, imgp->ip_envc,
imgp->ip_endenvv - imgp->ip_endargv);
/* reset local idea of thread, uthread, task */
thread = imgp->ip_new_thread;
uthread = get_bsdthread_info(thread);
task = new_task = get_threadtask(thread);
// 注意点:
lret = load_machfile(imgp, mach_header, thread, &map, &load_result);
... 省略无数
整个代码都没啥用,就是做些检查,分配个进程壳,然后通过load_machfile加载真正的二进制文件。
load_return_t
load_machfile(
struct image_params *imgp,
struct mach_header *header,
thread_t thread,
vm_map_t *mapp,
load_result_t *result
)
{
... 省略一大堆
if (macho_size > file_size) {
return(LOAD_BADMACHO);
}
result->is64bit = ((imgp->ip_flags & IMGPF_IS_64BIT) == IMGPF_IS_64BIT);
task_t ledger_task;
if (imgp->ip_new_thread) {
ledger_task = get_threadtask(imgp->ip_new_thread);
} else {
ledger_task = task;
}
// 注意点1
pmap = pmap_create(get_task_ledger(ledger_task),
(vm_map_size_t) 0,
result->is64bit);
// 注意点2
map = vm_map_create(pmap,
0,
vm_compute_max_offset(result->is64bit),
TRUE);
#if defined(__arm64__)
// 注意点三
if (result->is64bit) {
/* enforce 16KB alignment of VM map entries */
vm_map_set_page_shift(map, SIXTEENK_PAGE_SHIFT);
} else {
vm_map_set_page_shift(map, page_shift_user32);
}
- 利用
pmap_create创建硬件相关的物理内存抽象。 - 利用
vmap_create创建虚拟内存的地址图。 - ARM64下的页是16k一个虚拟页对应一个物理页。
别的没啥关注,我们重点关注vm_map_create0和vm_compute_max_offset(result->is64bit)。
因为这个代表了这个任务分配的虚拟地址上下限!这个函数的实现如下:
vm_map_offset_t
vm_compute_max_offset(boolean_t is64)
{
#if defined(__arm__) || defined(__arm64__)
return (pmap_max_offset(is64, ARM_PMAP_MAX_OFFSET_DEVICE));
#else
return (is64 ? (vm_map_offset_t)MACH_VM_MAX_ADDRESS : (vm_map_offset_t)VM_MAX_ADDRESS);
#endif
}
继续往下看:
vm_map_offset_t pmap_max_offset(
boolean_t is64 __unused,
unsigned int option)
{
vm_map_offset_t max_offset_ret = 0;
#if defined(__arm64__)
assert (is64);
vm_map_offset_t min_max_offset = SHARED_REGION_BASE_ARM64 + SHARED_REGION_SIZE_ARM64 + 0x20000000; // end of shared region + 512MB for various purposes
if (option == ARM_PMAP_MAX_OFFSET_DEFAULT) {
max_offset_ret = arm64_pmap_max_offset_default;
} else if (option == ARM_PMAP_MAX_OFFSET_MIN) {
max_offset_ret = min_max_offset;
} else if (option == ARM_PMAP_MAX_OFFSET_MAX) {
max_offset_ret = MACH_VM_MAX_ADDRESS;
} else if (option == ARM_PMAP_MAX_OFFSET_DEVICE) {
if (arm64_pmap_max_offset_default) {
max_offset_ret = arm64_pmap_max_offset_default;
} else if (max_mem > 0xC0000000) {
max_offset_ret = 0x0000000318000000ULL; // Max offset is 12.375GB for devices with > 3GB of memory
} else if (max_mem > 0x40000000) {
max_offset_ret = 0x0000000218000000ULL; // Max offset is 8.375GB for devices with > 1GB and <= 3GB of memory
} else {
max_offset_ret = min_max_offset;
}
} else if (option == ARM_PMAP_MAX_OFFSET_JUMBO) {
max_offset_ret = 0x0000000518000000ULL; // Max offset is 20.375GB for pmaps with special "jumbo" blessing
} else {
panic("pmap_max_offset illegal option 0x%x\n", option);
}
assert(max_offset_ret >= min_max_offset);
return max_offset_ret;
其实关键点就是这里的代码:
if (max_mem > 0xC0000000) {
max_offset_ret = 0x0000000318000000ULL; // Max offset is 12.375GB for devices with > 3GB of memory
} else if (max_mem > 0x40000000) {
max_offset_ret = 0x0000000218000000ULL; // Max offset is 8.375GB for devices with > 1GB and <= 3GB of memory
} else {
max_offset_ret = min_max_offset;
}
max_offset_ret这个值就代表了我们任务对应的vm_map_t的最大地址范围,比如说这里是8.375GB。
虚拟内存分配的限制
好,在说了那么多前置知识后,我们言归正传,来谈谈为什么虚拟内存有限制。
之前我们提到了large_malloc会走入到最后的vm_map_enter,那么我们来看看vm_map_enter的实现:
vm_map_enter(
vm_map_t map,
vm_map_offset_t *address, /* IN/OUT */
vm_map_size_t size,
vm_map_offset_t mask,
int flags,
vm_map_kernel_flags_t vmk_flags,
vm_tag_t alias,
vm_object_t object,
vm_object_offset_t offset,
boolean_t needs_copy,
vm_prot_t cur_protection,
vm_prot_t max_protection,
vm_inherit_t inheritance)
{
#if CONFIG_EMBEDDED
// 注意点1:检查页的权限
if (cur_protection & VM_PROT_WRITE){
if ((cur_protection & VM_PROT_EXECUTE) && !entry_for_jit){
printf("EMBEDDED: %s: curprot cannot be write+execute. "
"turning off execute\n",
__FUNCTION__);
cur_protection &= ~VM_PROT_EXECUTE;
}
}
#endif /* CONFIG_EMBEDDED */
if (resilient_codesign || resilient_media) {
if ((cur_protection & (VM_PROT_WRITE | VM_PROT_EXECUTE)) ||
(max_protection & (VM_PROT_WRITE | VM_PROT_EXECUTE))) {
return KERN_PROTECTION_FAILURE;
}
}
// 1. 获取任务的可用的地址最小值和最大值
effective_min_offset = map->min_offset;
effective_max_offset = map->max_offset;
if (map->pmap == kernel_pmap) {
user_alias = VM_KERN_MEMORY_NONE;
} else {
user_alias = alias;
}
#define RETURN(value) { result = value; goto BailOut; }
assert(page_aligned(*address));
assert(page_aligned(size));
if (!VM_MAP_PAGE_ALIGNED(size, VM_MAP_PAGE_MASK(map))) {
clear_map_aligned = TRUE;
}
StartAgain: ;
start = *address;
if (anywhere) {
vm_map_lock(map);
map_locked = TRUE;
if (start < effective_min_offset)
start = effective_min_offset;
if (start > effective_max_offset)
RETURN(KERN_NO_SPACE);
if( FALSE ) {
} else {
if (map->holelistenabled) {
hole_entry = (vm_map_entry_t)map->holes_list;
if (hole_entry == NULL) {
/*
* No more space in the map?
*/
result = KERN_NO_SPACE;
goto BailOut;
} else {
boolean_t found_hole = FALSE;
do {
if (hole_entry->vme_start >= start) {
start = hole_entry->vme_start;
found_hole = TRUE;
break;
}
if (hole_entry->vme_end > start) {
found_hole = TRUE;
break;
}
hole_entry = hole_entry->vme_next;
} while (hole_entry != (vm_map_entry_t) map->holes_list);
if (found_hole == FALSE) {
result = KERN_NO_SPACE;
goto BailOut;
}
entry = hole_entry;
if (start == 0)
start += PAGE_SIZE_64;
}
}
}
while (TRUE) {
vm_map_entry_t next;
end = ((start + mask) & ~mask);
end = vm_map_round_page(end,
VM_MAP_PAGE_MASK(map));
if (end < start)
RETURN(KERN_NO_SPACE);
start = end;
end += size;
if ((end > effective_max_offset) || (end < start)) {
RETURN(KERN_NO_SPACE);
}
next = entry->vme_next;
if (map->holelistenabled) {
if (entry->vme_end >= end)
break;
} else {
if (next == vm_map_to_entry(map))
break;
if (next->vme_start >= end)
break;
}
entry = next;
if (map->holelistenabled) {
if (entry == (vm_map_entry_t) map->holes_list) {
result = KERN_NO_SPACE;
goto BailOut;
}
start = entry->vme_start;
} else {
start = entry->vme_end;
}
start = vm_map_round_page(start,
VM_MAP_PAGE_MASK(map));
}
if (map->holelistenabled) {
if (vm_map_lookup_entry(map, entry->vme_start, &entry)) {
panic("Found an existing entry (%p) instead of potential hole at address: 0x%llx.\n", entry, (unsigned long long)entry->vme_start);
}
}
*address = start;
}
- 注意点1:基本上就是检查页的权限啥的,iOS上不允许可写和可执行并存。
- 剩下的就是作各种前置检查
老实说,我一开始看苹果这最新的XNU代码,我压根没读懂。这一堆hole啥的在干啥,后来我就往之前XNU版本翻了翻,果然好懂了很多:
entry = map->first_free;
if (entry == vm_map_to_entry(map)) {
entry = NULL;
} else {
if (entry->vme_next == vm_map_to_entry(map)){
entry = NULL;
} else {
if (start < (entry->vme_next)->vme_start ) {
start = entry->vme_end;
start = vm_map_round_page(start,
VM_MAP_PAGE_MASK(map));
} else {
entry = NULL;
}
}
}
if (entry == NULL) {
vm_map_entry_t tmp_entry;
if (vm_map_lookup_entry(map, start, &tmp_entry)) {
assert(!entry_for_jit);
start = tmp_entry->vme_end;
start = vm_map_round_page(start,
VM_MAP_PAGE_MASK(map));
}
entry = tmp_entry;
}
整个这段代码的意思是,就是要我们要找个一个比我们这个
start地址大的vm_entry_t。(这句话比较绕口),我们最终的目的是为了在两个已经存在vm_entry_t之间尝试插入一个能包含从start到start + size的新的vm_entry_t如果没找到的话,就尝试利用
vm_map_lookup_entry找一个preceding我们地址的的vm_entry_t。
好,现在我们找到了一个满足start其实地址条件的vm_entry_t了,剩下就是要满足分配大小size的需求了。
while (TRUE) {
register vm_map_entry_t next;
end = ((start + mask) & ~mask);
end = vm_map_round_page(end,
VM_MAP_PAGE_MASK(map));
if (end < start)
RETURN(KERN_NO_SPACE);
start = end;
end += size;
if ((end > effective_max_offset) || (end < start)) {
RETURN(KERN_NO_SPACE);
}
next = entry->vme_next;
// 如果是空的头
if (next == vm_map_to_entry(map))
break;
// 如果下一个的start
if (next->vme_start >= end)
break;
entry = next;
start = entry->vme_end;
start = vm_map_round_page(start,
VM_MAP_PAGE_MASK(map));
}
*address = start;
assert(VM_MAP_PAGE_ALIGNED(*address,
VM_MAP_PAGE_MASK(map)));
这段代码相对来说就很简单了,我们判断start + size是不是可以正好插入在vm_entry_t代表的地址范围的空隙内,如果一直遍历到最后的任务地址上限都找不到,那就说明不存在我们需求的连续的虚拟内存空间用于作分配了。
其他
除了本文说明的虚拟内存分配的连续性限制以外,虚拟内存作为堆内存分配的一种,在布局范围上也有限制。此文不表,且听下回分解。