关于Objective-C中的@Synchronized,想必从事iOS开发相关工作的同学都不陌生,可以说这是一种最简单的加锁的方式了。
网上关于锁对比的文章也不在少数,太多说集中在用法概述以及性能对比。而@Synchronized在不少文章中常常因其性能而被建议不要使用。
本质上来说,在客户端场景下,高密度使用锁的场景是相对较少(比如IM数据库除外);同时,抛开使用场景单独通过比如for循环测试锁的性能,也是比较蛋疼的,不合适的用法、过大的锁范围以及竞态条件,都会导致比较条件的欠考虑性。
因此,今天我想谈谈一个不应该使用@Synchronized的本质原因:它是一个和上下文强相关的锁,会导致锁失效。
一个简单的事例
考虑一个场景:
我们后台静默更新一下数据,一旦有了新数据,就整体替换掉现在呈现的数据,这在列表页配合远程数据的时候非常常见。
为了放大多线程可能出错的场景,我放大到5000个线程,构造如下代码:
@interface ViewController ()
@property (nonatomic, strong) NSMutableArray *testArray;
@end
@implementation ViewController
- (void)viewDidLoad
{
[super viewDidLoad];
self.testArray = @[].mutableCopy;
for (NSUInteger i = 0; i < 5000; i++) {
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{
[self testThreadArray];
});
}
}
- (void)testThreadArray
{
@synchronized (self.testArray) {
self.testArray = @[].mutableCopy;
}
}
可以看出,为了避免多个线程同时更新临界资源testArray,我们使用 @synchronized (self.testArray) 进行了资源保护。
备注:为什么需要保护这里的赋值操作,可以阅读我的从Immutable来谈谈对于线程安全的理解误区
看起来一切都很Ok,但是当你实际运行代码,还是会出现野指针Crash。如下图所示:
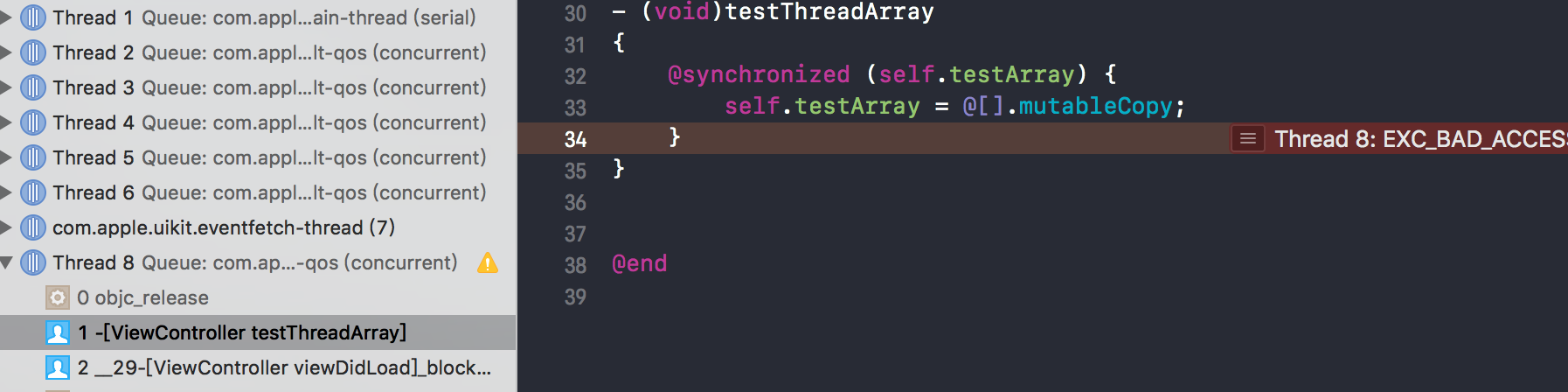
这里用
@Synchronized(self)是可以成功锁住的,但是这会陷入到锁的范围太大的场景中去,不再此文探讨的范围内。
Crash的根因
@Synchronized会变成一对基于try-catch的objc_sync_enter和objc_sync_exit的代码,想必都不陌生了,许多网上文章都有,不再赘述,可以参考clang的代码:
/// RewriteObjCSynchronizedStmt -
/// This routine rewrites @synchronized(expr) stmt;
/// into:
/// objc_sync_enter(expr);
/// @try stmt @finally { objc_sync_exit(expr); }
///
Stmt *RewriteObjC::RewriteObjCSynchronizedStmt(ObjCAtSynchronizedStmt *S) {
// Get the start location and compute the semi location.
SourceLocation startLoc = S->getBeginLoc();
const char *startBuf = SM->getCharacterData(startLoc);
assert((*startBuf == '@') && "bogus @synchronized location");
std::string buf;
buf = "objc_sync_enter((id)";
const char *lparenBuf = startBuf;
while (*lparenBuf != '(') lparenBuf++;
ReplaceText(startLoc, lparenBuf-startBuf+1, buf);
// We can't use S->getSynchExpr()->getEndLoc() to find the end location, since
// the sync expression is typically a message expression that's already
// been rewritten! (which implies the SourceLocation's are invalid).
SourceLocation endLoc = S->getSynchBody()->getBeginLoc();
const char *endBuf = SM->getCharacterData(endLoc);
while (*endBuf != ')') endBuf--;
SourceLocation rparenLoc = startLoc.getLocWithOffset(endBuf-startBuf);
buf = ");\n";
// declare a new scope with two variables, _stack and _rethrow.
buf += "/* @try scope begin */ \n{ struct _objc_exception_data {\n";
buf += "int buf[18/*32-bit i386*/];\n";
buf += "char *pointers[4];} _stack;\n";
buf += "id volatile _rethrow = 0;\n";
buf += "objc_exception_try_enter(&_stack);\n";
buf += "if (!_setjmp(_stack.buf)) /* @try block continue */\n";
ReplaceText(rparenLoc, 1, buf);
startLoc = S->getSynchBody()->getEndLoc();
startBuf = SM->getCharacterData(startLoc);
assert((*startBuf == '}') && "bogus @synchronized block");
SourceLocation lastCurlyLoc = startLoc;
buf = "}\nelse {\n";
buf += " _rethrow = objc_exception_extract(&_stack);\n";
buf += "}\n";
buf += "{ /* implicit finally clause */\n";
buf += " if (!_rethrow) objc_exception_try_exit(&_stack);\n";
std::string syncBuf;
syncBuf += " objc_sync_exit(";
Expr *syncExpr = S->getSynchExpr();
CastKind CK = syncExpr->getType()->isObjCObjectPointerType()
? CK_BitCast :
syncExpr->getType()->isBlockPointerType()
? CK_BlockPointerToObjCPointerCast
: CK_CPointerToObjCPointerCast;
syncExpr = NoTypeInfoCStyleCastExpr(Context, Context->getObjCIdType(),
CK, syncExpr);
std::string syncExprBufS;
llvm::raw_string_ostream syncExprBuf(syncExprBufS);
assert(syncExpr != nullptr && "Expected non-null Expr");
syncExpr->printPretty(syncExprBuf, nullptr, PrintingPolicy(LangOpts));
syncBuf += syncExprBuf.str();
syncBuf += ");";
buf += syncBuf;
buf += "\n if (_rethrow) objc_exception_throw(_rethrow);\n";
buf += "}\n";
buf += "}";
ReplaceText(lastCurlyLoc, 1, buf);
bool hasReturns = false;
HasReturnStmts(S->getSynchBody(), hasReturns);
if (hasReturns)
RewriteSyncReturnStmts(S->getSynchBody(), syncBuf);
return nullptr;
}
卧槽,原来
clang的rewrite部分也写的这么挫逼啊。
我们就从objc_sync_enter来继续挖掘:
if (obj) {
SyncData* data = id2data(obj, ACQUIRE);
assert(data);
data->mutex.lock();
}
关键其实就是在于从obj转换到SyncData,然后通过SyncData中的mutex来进行临界区的锁。
有两个部分需要分析一下,首先SyncData结构体定义如下:
typedef struct alignas(CacheLineSize) SyncData {
struct SyncData* nextData;
DisguisedPtr<objc_object> object;
int32_t threadCount; // number of THREADS using this block
recursive_mutex_t mutex;
} SyncData;
mutex,一把递归锁,这也是为什么我们可以在@Synchronized里面嵌套@Synchronized的原因。DisguisedPtr,还记得我们以前写安全气垫的时候给一些释放的内存地址填充0x55用于拦截use after free的场景?这里DisguisedPtr其实就是对裸对象指针objc_object的一层包装改写。
继续回到id2data函数往下研究,可以发现一段比较有意思的函数:
static StripedMap<SyncList> sDataLists;
我们具体就关注[]对应的操作即可:
class StripedMap {
#if TARGET_OS_IPHONE && !TARGET_OS_SIMULATOR
enum { StripeCount = 8 };
#else
enum { StripeCount = 64 };
#endif
struct PaddedT {
T value alignas(CacheLineSize);
};
PaddedT array[StripeCount];
static unsigned int indexForPointer(const void *p) {
uintptr_t addr = reinterpret_cast<uintptr_t>(p);
return ((addr >> 4) ^ (addr >> 9)) % StripeCount;
}
public:
T& operator[] (const void *p) {
return array[indexForPointer(p)].value;
}
const T& operator[] (const void *p) const {
return const_cast<StripedMap<T>>(this)[p];
}
抽丝剥茧,这里其实就是一个简单的Hash算法,然后将传入的对象地址,通过indexForPointer映射到不同的SyncList上。而SyncList是一个维护SyncData的链表,每个SyncList都单独维护操作自己的lock。
indexForPointer公式:((addr >> 4) ^ (addr >> 9)) % StripeCount,其中StripeCount是个数。
这样做的好处就是创建了一个所谓的散列锁,可以有效的降低不同的对象操作指尖的相互影响性。当然,从本质上看,iOS上就8个散列锁,这也是影响大规模使用@Synchronized会影响性能的原因之一。
接着往下走,我们直接关注没有命中Thread Local Storage的场景。
#define LOCK_FOR_OBJ(obj) sDataLists[obj].lock
spinlock_t *lockp = &LOCK_FOR_OBJ(object);
// 通过对对象地址hash,算法对应SyncList的锁
lockp->lock();
{
SyncData* p;
SyncData* firstUnused = NULL;
for (p = *listp; p != NULL; p = p->nextData) {
if ( p->object == object ) {
result = p;
// atomic because may collide with concurrent RELEASE
OSAtomicIncrement32Barrier(&result->threadCount);
goto done;
}
if ( (firstUnused == NULL) && (p->threadCount == 0) )
firstUnused = p;
}
// no SyncData currently associated with object
if ( (why == RELEASE) || (why == CHECK) )
goto done;
// an unused one was found, use it
// 关注点1 !!!!!!!!!!!!
if ( firstUnused != NULL ) {
result = firstUnused;
result->object = (objc_object *)object;
result->threadCount = 1;
goto done;
}
}
// Allocate a new SyncData and add to list.
// XXX allocating memory with a global lock held is bad practice,
// might be worth releasing the lock, allocating, and searching again.
// But since we never free these guys we won't be stuck in allocation very often.
// 关注点2 !!!!!!!!!!!!
posix_memalign((void **)&result, alignof(SyncData), sizeof(SyncData));
result->object = (objc_object *)object;
result->threadCount = 1;
new (&result->mutex) recursive_mutex_t(fork_unsafe_lock);
result->nextData = *listp;
*listp = result;
done:
lockp->unlock();
if (result) {
// Only new ACQUIRE should get here.
// All RELEASE and CHECK and recursive ACQUIRE are
// handled by the per-thread caches above.
if (why == RELEASE) {
// Probably some thread is incorrectly exiting
// while the object is held by another thread.
return nil;
}
if (why != ACQUIRE) _objc_fatal("id2data is buggy");
if (result->object != object) _objc_fatal("id2data is buggy");
// 关注点3
#if SUPPORT_DIRECT_THREAD_KEYS
if (!fastCacheOccupied) {
// Save in fast thread cache
tls_set_direct(SYNC_DATA_DIRECT_KEY, result);
tls_set_direct(SYNC_COUNT_DIRECT_KEY, (void*)1);
} else
#endif
{
// Save in thread cache
if (!cache) cache = fetch_cache(YES);
cache->list[cache->used].data = result;
cache->list[cache->used].lockCount = 1;
cache->used++;
}
}
return result;
- 通过散列,计算这个对象应该落入的
SyncList,由于需要操作SyncList,用其对应的锁进行加锁。
- 通过散列,计算这个对象应该落入的
- 关注点1和2,其实本质干的是一件事,就是找出一个可以被使用的
SyncData,如果没有就创建一个,设定好对应的成员变量,然后返回。
- 关注点1和2,其实本质干的是一件事,就是找出一个可以被使用的
- 关注点3,就是做完了以后,利用一下
Thread Local Storage,存一下,这块不关注无伤大雅。
- 关注点3,就是做完了以后,利用一下
Ok,到现在我们分析完成@Synchronized的实现原理后,我们可以回过头再来看看为什么对象被更改后会产生Crash了。
其实一言以蔽之,就是@Synchronized锁不住对象赋值变化的场景。
回到我们上一小节Crash的问题:
考虑三个线程的场景,分别定义为线程A,线程B,线程C,初始的时候在线程A,self.testArray的初始值为arr0(实质上操作的是arr0地址,下文简述为arr0),我们来理下时间线:
- 线程A获取
self.testArray的值,为arr0。 - 线程B获取
self.testArray的值,也为arr0。 - 线程A,B由于对象地址一致,产生竞争,A获取到了对应的锁,我们称之为
lock0。 - 线程A在锁的保护下,执行
self.testArray = @[].mutableCopy。self.testArray指向了arr1。 - 线程Aunlock。
- 此时线程C开始尝试获取
self.testArray,获取到了arr1。 - 这个时候线程B由于线程A释放锁了,线程B继续,线程B使用之前获取的
arr0进行获取锁的操作。 - 这个时候线程C也尝试进行锁操作,由于线程C是
arr1,所以使用的是arr1对应的锁操作。 - 由于
arr0和arr1对应的锁不是一个(当然理论上可能散列计算为同一个),所以这两个线程都进入了临界区 - 线程B和线程C都执行
self.testArray = @[].mutableCopy。 Setter的赋值并不是atomic的,实质上会转换成如下这样的代码:static inline void reallySetProperty(id self, SEL _cmd, id newValue, ptrdiff_t offset, bool atomic, bool copy, bool mutableCopy) { id oldValue; // 计算结构体中的偏移量 id *slot = (id*) ((char*)self + offset); if (copy) { newValue = [newValue copyWithZone:NULL]; } else if (mutableCopy) { newValue = [newValue mutableCopyWithZone:NULL]; } else { // 某些程度的优化 if (*slot == newValue) return; newValue = objc_retain(newValue); } // 危险区 if (!atomic) { // 第一步 oldValue = *slot; // 第二步 *slot = newValue; } else { spin_lock_t *slotlock = &PropertyLocks[GOODHASH(slot)]; _spin_lock(slotlock); oldValue = *slot; *slot = newValue; _spin_unlock(slotlock); } objc_release(oldValue); }在上述危险区的第二步,
_testArray在线程B和线程C分别指向了新地址addr2和addr3,但是获取到的oldValue可能都是arr1- 通过
objc_release对oldValue,也就是arr1进行了两次释放,妥妥的double free过度释放场景,导致崩溃。
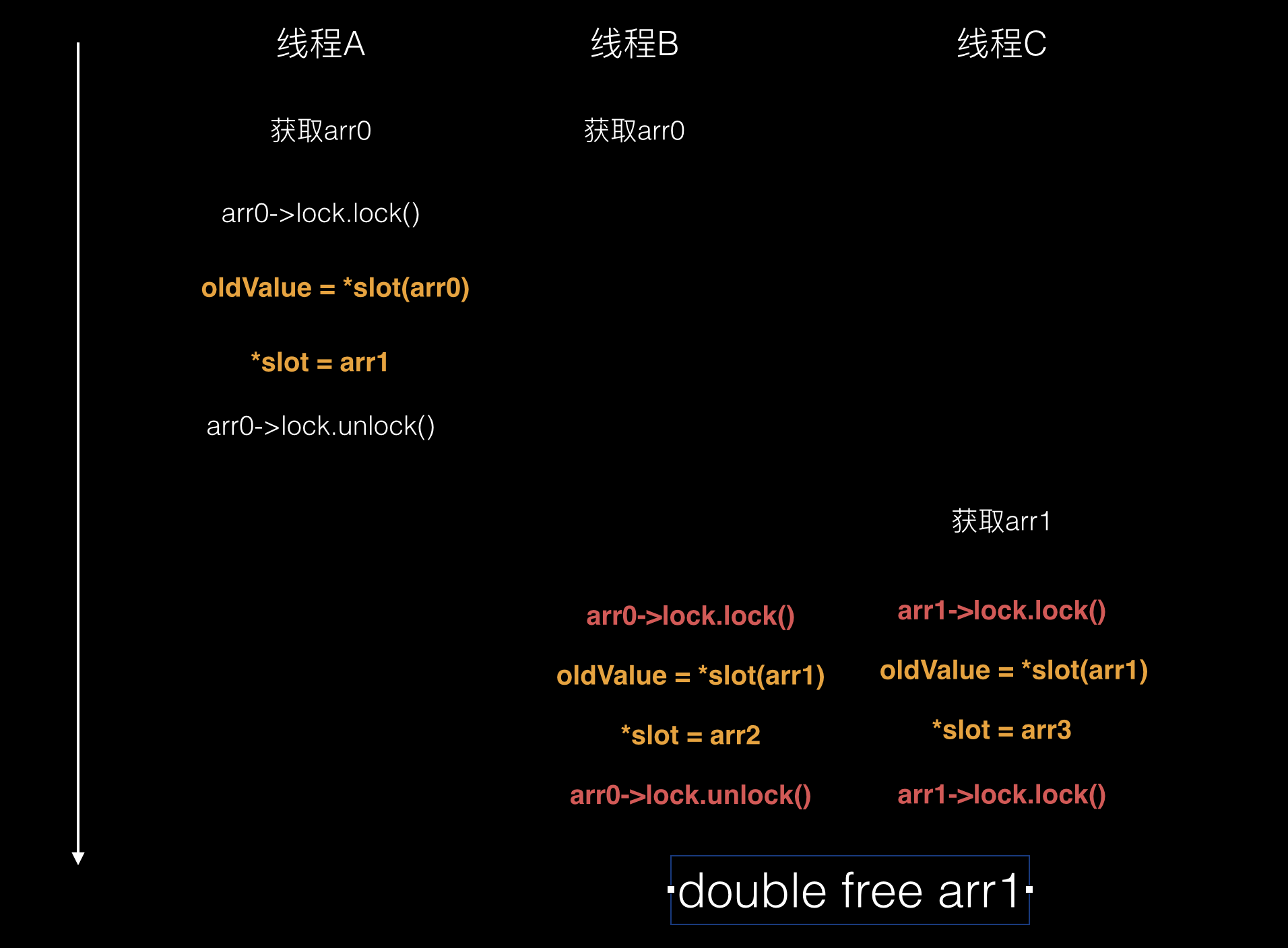
备注:多线程的场景在于不确定性,可能在其中任何一个指令处挂掉。
结语
所以,从本质上来说,@Synchronized的确是最不应该推荐给用户使用的一种锁机制,但是其根本原因并不一定是性能差距,Hash离散设计的优雅的话,一样能保证性能。但是其内在锁和对象上下文相关的联系会导致锁失效的场景,一旦有对象发生变化(被赋值),导致潜在的锁不住多线程的场景,我们也应该去了解学习。