新的一个财年加入了新的组,从事机器学习相关的工作。由于之前做的一直是iOS(略微底层)方面的事情,初来乍到,对很多东西不熟悉,在超级大神ZB的建议下,用C++实现一个多层前馈神经网络,来识别MNIST数据中的各种手写图片。
素材寻找
- 感谢这位不知名的大佬提供的MNIST数据集,可以直接下载纯图片数据集
- 搜索下载已经调整好的
weight和bias模型。(下文会介绍)
实现过程
关于实现多层前馈神经网络,网络上的答案数不胜数,但是大多数都是参考Tensorflow或者Caffe(PyTorch)去实现,我觉得这样很不好。因为学习一门新技术,虽然快速完成项目看出效果很重要,但是对个人来说,弄懂黑盒背后的故事非常重要。因此我决定不依赖任何的库来完全裸写。
当然,对于我来说,实现的完整度和正确性是第一位的,我并没有过多的关注性能。
虽然在深度学习高度发展的今天,类似于AlexNet这样的网络模型能够近乎完美的识别手写数据集。但是作为这个领域的入门级选手,我还是想追溯起源,从头开始做起。因此,在一番学习和搜索后,我选定了LeNet-5模型进行编写。选择它的原因主要有如下几点:
- 它自身是一个多层的前馈网络模型。
- 麻雀虽小,五脏俱全。包含了卷积层、全联接层、放缩、灰度以及池化层。同时还引入了
ReLu,Softmax等激活函数。 - 实现简单,哈哈哈哈哈
LeNet-5
LeNet-5整体是个非常简单的过程,包含如下步骤:
- 接受一个RGBA的图像。这个很简单,直接在RGBA的颜色空间下读取即可。
- 放缩到28 * 28(保留所有的feature)的大小,采用的是
bilinear插值方法。 - 灰度化,公式如下:
r / 255.0 * 0.299 + g / 255.0 * 0.587 + b /255.0 * 0.114。 - 取反,即
255.0 - 灰度化的结果 - 5 * 5大小的卷积,加
Relu,进行第一次卷积操作。(这里为了保证卷积后尺寸一致,添加了Padding) - 最大池化层降采样。
- 5 * 5大小的进行第二次卷积,加
ReLu,进行第一次卷积操作。(这里为了保证卷积后尺寸一致,添加了Padding) - 最大池化层降采样。
- 全链接计算 +
ReLu - 全链接输出10个
featureMap Softmax计算并去除最大的值,即为检测的数字结果。
整体实现上没什么需要特别注意的,如果对这里的名次不懂,可以上网自行查询对应的解释。不过这里有一点很不好,浪费了大量的时间在调试我定义的张量的格式和网上找到的weight模型的格式。
什么意思呢?我大致用如下的图解释下我自身设计的张量是如何存储的。
理论上来讲,张量有三个维度,width, height, featureChannels。我在设计我的张量存储上按照的data[height][row][featureChannels]的方式,然后全部拍成了一维。如图所示:

之所以想这么做,主要是瞄了眼
TensorFlow也是类似的设计,然后印象中CUDA也是按照这样维度进行存储,貌似可以有效做并行计算拆分。(这个不确定)
然后为什么卡了很久呢?主要是weights和bias的模型文件是个按照自定义协议二进制流的文件(非结构化的数据)。
这模型由于是我网上找的,一开始没注意模型的自定义协议和我设计的张量直接的区别。我直接按照我的张亮顺序进行了相乘,得到了十分错误的结果。
当然,bias模型没什么好说的,就是按照outputFeatureMap定义的纯一维数组,不会出错。
后来发现这个模型是基于苹果的MPS设计的模型,它的模型是这样的数据结构weights[outputChannels][height][width][inputChannel/group]。第一维在计算的时候需要和我做个映射,所以这里没搞清楚模型格式,查了比较久。
当然,我在加载权重和bias这块还是做了点小油画。用了mmap,避免一次性直接搞进来太大的数据,反正看起来weight和bias这块并不需要一次性的读取,而且只读的mmap还能合理利用iOS设备上的clean memory回收机制。
框架设计
网络模型拓扑结构,
MinstGraph。这里偷懒了,因为LeNet-5也没啥复杂的拓扑结构,不用考虑多个节点连接,直接线性跑下去就好。支持任意多维度的张量,类似
Tensorflow里面的Tensor,这里对应了MinstImage。- 各种Layer,如
MaxPoolingLayer,ConvolutionLayer,FullConnectionLayer等等。 - 各种激活函数,如
Relu,Softmax等等。 - 一些辅助函数之类的。
代码下周发吧。
效果
准确度一开始不怎么高,检查了很多遍代码,确实发现了一些问题,比如数据精度问题。
一开始从图像的角度理解,认为用unsigned char存储一个数据点就够了,毕竟图像像素点(RGB空间下)的取值范围就是0-255。
后来发现在计算卷积、全链接层的时候会产生很多小数,用unsigned char存储精度全部丢失了。因此修改成了现在的float设计。对效果提升还是比较明显的。
后来专门跑了下苹果基于Metal实现的卷积神经网络,由于上述我自身实现的所有Layer和激活函数在苹果的框架中都有内置,因此把网络模型搭起来跑就完了(除非苹果自己实现有错)。然后对比我的每一层输入输出和对应的MPSImage输入输出。
不过这里有一点要注意,MPSImage的数据格式是NHWC,这里的N是把C按照4对齐后分成的不同batch。如下图所示:

假设是一个2 * 1 * 5(w h c)的数据,会先把前4层排完,再进行第五层的排列,按4对齐后多出来的三个层补0。
我的代码里面MinstImage提供了一个print方法就是专门做输出对比的。嗯,对比了我的实现和用苹果框架的下输入输出,结果是一致的。(除了iOS10上不支持bilinear插值)
最终效果如下图:
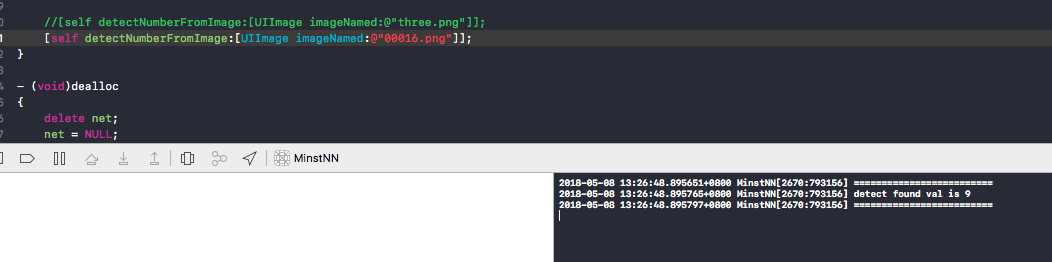
备注:
如果直接用我开头提到的MNIST数据集,由于每张图都是28 * 28的灰度图,因此不需要resize + grayscale,直接从取反开始计算就可以了。
后续规划
做神经网络还是挺有意思,不过目前还是参考简单的模型结构实现,主要做
inference。还没真正去研究训练模型这块。这块需要多深入研究算法,多读论文。目前并没有真正设计
Session的概念。理论上一张图就是一个静态的拓扑结构的组合而已,不应该承担类似执行run的功能。后续业余时间还会继续实现完整这套逻辑,将静态结构和动态执行结构彻底分离。后续有时间的话,可以尝试实现别的模型。同时支持从文件中读取已经建立好的模型,类似Caffee模型之类的
移植到GPU上。
最后
文章的最后,按照惯例还是向我的偶像致敬。机器学习发展到今天,已经成为了不可忽视的研究方向。对于我们这样的后生来说,站在大牛的肩膀上是我们的福气和基石。而像杨萧玉这样,能够一周时间内学完机器学习课程,发表博客造福大众,才是推动机器学习不断发展的中坚力量。相信在他的带领下,我们国家一定能够在2030年达到全球领先的AI技术水准。