本文的硬核在第二段
之前在做某项目的时候,自建了基于NSThread的私有线程池,在线程池分配了固定个数的常驻工作线程,在工作线程里面运行相关任务;这个方案取代了原先直接无脑使用GCD的方式,在各方面效果都还不错。
但是在一次偶然的情况下,通过Memory Graph发现很多任务对象却在本该早就销毁的时候仍然存活着。持有其的对象是autorelease content,如下图所示:
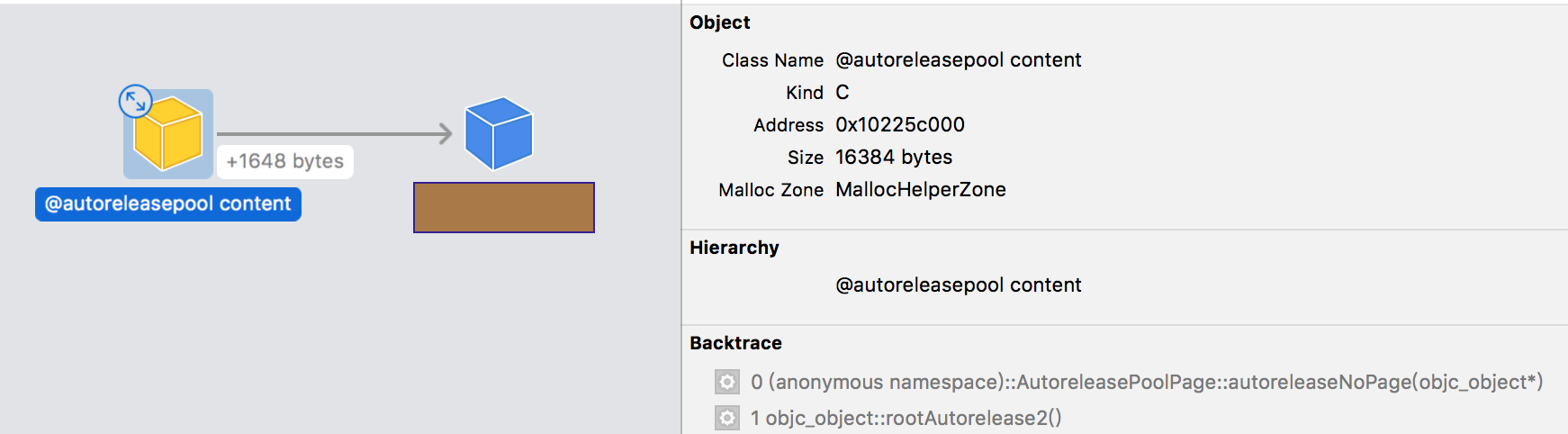
我把数据对象类型隐藏了,公司数据还是要保密。
那这个东西究竟是个啥呢?
由于其是黄色图标,基本上是一个容器类型或其子类。
这个类型@autoreleasepool content先不管,先从右边的堆栈来看:
- 某个方法调用了
autorelease相关的API - 由于我是在子线程触发的,没有显示创建的
autoreleasepool。因此需要调用autoreleaseNoPage
而autoreleaseNoPage其实本质上就是在当前线程没有autoreleasePage的时候,创建一个。然后通过Thread Local Storage存入线程相关上下文中。
static __attribute__((noinline))
id *autoreleaseNoPage(id obj)
{
// "No page" could mean no pool has been pushed
// or an empty placeholder pool has been pushed and has no contents yet
assert(!hotPage());
bool pushExtraBoundary = false;
if (haveEmptyPoolPlaceholder()) {
// We are pushing a second pool over the empty placeholder pool
// or pushing the first object into the empty placeholder pool.
// Before doing that, push a pool boundary on behalf of the pool
// that is currently represented by the empty placeholder.
pushExtraBoundary = true;
}
else if (obj != POOL_BOUNDARY && DebugMissingPools) {
// We are pushing an object with no pool in place,
// and no-pool debugging was requested by environment.
_objc_inform("MISSING POOLS: (%p) Object %p of class %s "
"autoreleased with no pool in place - "
"just leaking - break on "
"objc_autoreleaseNoPool() to debug",
pthread_self(), (void*)obj, object_getClassName(obj));
objc_autoreleaseNoPool(obj);
return nil;
}
else if (obj == POOL_BOUNDARY && !DebugPoolAllocation) {
// We are pushing a pool with no pool in place,
// and alloc-per-pool debugging was not requested.
// Install and return the empty pool placeholder.
return setEmptyPoolPlaceholder();
}
// We are pushing an object or a non-placeholder'd pool.
// Install the first page.
AutoreleasePoolPage *page = new AutoreleasePoolPage(nil);
setHotPage(page);
// Push a boundary on behalf of the previously-placeholder'd pool.
if (pushExtraBoundary) {
page->add(POOL_BOUNDARY);
}
// Push the requested object or pool.
return page->add(obj);
}
同时由于是第一个page,连父子关系都不用串联,非常简单。
但是,其他线程有一点相对主线程比较坑的就是子线程默认没有runloop,导致在释放被autoreleasepool的对象的时候产生着问题。
那么子线程的autoreleasepool在没有runloop的情况下何时释放呢?
- 线程退出的时候
- 局部
autoreleasepool drain的时候
第二点比较好理解,就是常规的page push以及对应的page pop。
那么线程退出释放是如何确定的呢?我们在线程退出的时候下个断点:
static void tls_dealloc(void *p)
{
if (p == (void*)EMPTY_POOL_PLACEHOLDER) {
// No objects or pool pages to clean up here.
return;
}
// reinstate TLS value while we work
setHotPage((AutoreleasePoolPage *)p);
if (AutoreleasePoolPage *page = coldPage()) {
if (!page->empty()) pop(page->begin()); // pop all of the pools
if (DebugMissingPools || DebugPoolAllocation) {
// pop() killed the pages already
} else {
page->kill(); // free all of the pages
}
}
// clear TLS value so TLS destruction doesn't loop
setHotPage(nil);
}
而在runtime初始化的过程中,会调用AutoReleasePoolPage::init方法注册tls_dealloc:
static void init()
{
int r __unused = pthread_key_init_np(AutoreleasePoolPage::key,
AutoreleasePoolPage::tls_dealloc);
assert(r == 0);
}
结合这两段代码,我们大致可以猜测下phtread_key_init_np是将tls_dealloc注册给某个回调使用。那具体是干嘛的?
实际上phtread_key_init_np时给thread注册了线程销毁时的自定义析构函数,这里我们可以一起来看看darwin-apple的libpthread代码,这里我直接简化掉流程,输出大致的过程:
_pthread_exit 在线程销毁时调用 -> _pthread_tsd_cleanup -> _pthread_tsd_cleanup_new -> _pthread_tsd_cleanup_key。
在最终的函数里,会遍历所有的自定义销毁函数,逐个触发:
static void
_pthread_tsd_cleanup_key(pthread_t self, pthread_key_t key)
{
void (*destructor)(void *);
if (_pthread_key_get_destructor(key, &destructor)) {
void **ptr = &self->tsd[key];
void *value = *ptr;
if (value) {
*ptr = NULL;
if (destructor) {
destructor(value);
}
}
}
}
因此,对于我这样设计了常驻线程的“不死线程”来说,无法指望线程销毁时候的释放,必须自己引入autoreleasepool来修正内存没释放干净!
到底哪些东西会触发autorelease持有?
本文的重点来了。
其实网上关于autoreleasepage相关的文章分析的很多了,我这篇文章的主要目的还是想思考下,看看平常无奇的代码,究竟会在什么情况下触发autorelease及其相关行为。如果说所有的东西都是直接了当的引用计数相加减如objc_storeStrong / objc_storeStrong(nil),何须多此一举引入autorelease呢?
网上许多的文章的结论基本上都是:
编译器为判断方法名是否是以
alloc/new/copy/mutableCopy开头,如果不是,就自动将返回的对象注册到池子中。
编译器会在objc_autoreleaseReturnValue和objc_retainAutoreleasedReturnValue进行基于TLS的判断优化,本质上也不会走入autorelease的环节。
为了验证这些结论,我首先重温了下《iOS 内存高级编程》一书,它所阐述的都是内存管理的思想,以alloc/mew/copy/mutableCopy驼峰命名开头的方法,方法的对象由调用者自己持有;而其他方法是取得非自己生成并持有的对象
卧槽,真拗口。
写个Demo验证下,
@interface Model : NSObject
- (Model *)haha;
@end
- (Model *)haha
{
// 这里是为了避免调用系统库的对象可能在存在某些MRC的情况导致无法优化。
return [[Model alloc] init];
}
// 调用
Model *model = [[Model alloc] init];
Model *m2 = [model haha];
万变不如汇编,让我们先来看第一条调用的汇编代码。
0x100046768 <+96>: bl 0x100046b80 ; symbol stub for: objc_msgSend
0x10004676c <+100>: adrp x8, 2
0x100046770 <+104>: add x8, x8, #0xd38 ; =0xd38
0x100046774 <+108>: ldr x1, [x8]
0x100046778 <+112>: bl 0x100046b80 ; symbol stub for: objc_msgSend
0x10004677c <+116>: mov x8, #0x0
0x100046780 <+120>: add x9, sp, #0x8 ; =0x8
0x100046784 <+124>: str x0, [sp, #0x8]
0x100046788 <+128>: mov x0, x9
0x10004678c <+132>: mov x1, x8
0x100046790 <+136>: bl 0x100046bb0 ; symbol stub for: objc_storeStrong
很明显的,并没有涉及到任何的和retainAutorelease/autorelease相关的调用。
需要注意:在release优化下这里的
objc_storeStrong(nil)会直接优化成objc_release
而对于第二条调用,汇编如下:
0x10006275c <+140>: bl 0x100062b80 ; symbol stub for: objc_msgSend
0x100062760 <+144>: mov x29, x29
0x100062764 <+148>: bl 0x100062ba4 ; symbol stub for: objc_retainAutoreleasedReturnValue
关键字出现了,当然具体会不会进入autorelease的环节,还需要看优化的效果,我们进入haha函数看一看:
0x100096b28 <+36>: bl 0x100096b80 ; symbol stub for: objc_msgSend
0x100096b2c <+40>: adrp x1, 2
0x100096b30 <+44>: ldr x1, [x1, #0xd38]
0x100096b34 <+48>: bl 0x100096b80 ; symbol stub for: objc_msgSend
0x100096b38 <+52>: ldp x29, x30, [sp, #0x10]
0x100096b3c <+56>: add sp, sp, #0x20 ; =0x20
0x100096b40 <+60>: b 0x100096b74 ; symbol stub for: objc_autoreleaseReturnValue
也和我们预测的一样,确实有着objc_autoreleaseReturnValue,那么究竟会不会有基于TLS的优化行为呢?对objc_autoreleaseReturnValue下个符号断点:
libobjc.A.dylib`objc_autoreleaseReturnValue:
-> 0x18563e528 <+0>: ldr w8, [x30]
0x18563e52c <+4>: mov w9, #-0x55e30000
0x18563e530 <+8>: movk w9, #0x3fd
0x18563e534 <+12>: cmp w8, w9
0x18563e538 <+16>: b.ne 0x18563e550 ; <+40>
0x18563e53c <+20>: mrs x8, TPIDRRO_EL0
0x18563e540 <+24>: and x8, x8, #0xfffffffffffffff8
0x18563e544 <+28>: orr w9, wzr, #0x1
0x18563e548 <+32>: str x9, [x8, #0x160]
0x18563e54c <+36>: ret
0x18563e550 <+40>: b 0x18563c130 ; objc_autorelease
这里,偏移 +16的地方的b.ne就是对优化的判断,判断的条件是w8和w9的相等与否,不等就走传统的objc_autorelease。
这里经过断点我们发现确实走了优化。
那按照这个思路,难道真的在如今的ARC下,没有东西要进autoreleasepool了?那为什么还会在MemoryGraph中出现大量autorelease content呢?
答案可能出乎你的意料,for会影响这个autorelease优化逻辑。
我们构建一个两个线程的场景,Model类型如上述文章段落不变。构建一个符合类型Container,包含一个NSMutableArray的数组:
@interface Container()
@property (nonatomic, strong) NSMutableArray *models;
@end
@implementation Container
- (instancetype)init
{
self = [super init];
if (self) {
_models = @[].mutableCopy;
}
return self;
}
- (void)addModel:(Model *)model
{
if (!model) return;
[self.models addObject:model];
}
- (Model *)takeModel
{
//NSMutableArray *toOperateArray = self.models;
for (Model *model in self.models) {
}
Model *model = [self.models firstObject];
[self.models removeObject:model];
return model;
}
为了简化场景,我先在ViewController viewDidLoad塞入几个Model到Container,然后再启动第二个线程从Container中取Model。
测试场景如下:
- (void)viewDidLoad {
[super viewDidLoad];
self.container = [[Container alloc] init];
for (int i = 0; i < 10; i++) {
[self.container addModel:[[Model alloc] initWithCount:i]];
}
self.thread = [[NSThread alloc] initWithTarget:self selector:@selector(loop) object:nil];
[self.thread setName:@"com.walle.test"];
[self.thread start];
}
- (void)loop
{
while (true) {
Model *m = [self.container takeModel];
[m increment];
}
}
如果你执行我这段代码,你会发现的确如文章一开头所示,MemoryGraph中存在大量被@autoreleasepool content持有的Model。
那罪魁祸首是什么呢?从表象上看是这段并不起眼的代码:
for (Model *model in self.models) {
}
可具体原因是为啥呢?还是从汇编上来摸索下:
首先先回到没有汇编的场景上,调用的函数是-[ViewController loop],被调用者是-[Container takeModel:]
如果要进行优化,按照objc_autoreleaseReturnValue:的逻辑,在loop调用takeModel:的地方必须有对应的暗示:这个暗示在arm64中如下代码所示:
static ALWAYS_INLINE bool
callerAcceptsOptimizedReturn(const void *ra)
{
// fd 03 1d aa mov fp, fp
// arm64 instructions are well-aligned
if (*(uint32_t *)ra == 0xaa1d03fd) {
return true;
}
return false;
}
简单来说,要有mov fp, fp,而fp就是x29寄存器。那我们来看看loop的对应汇编:

哈哈,0x62b0的地方果然是mov x29, x29。
如果你对静态分析的结果不熟悉,可以动态进入汇编。在obc_autoreleaseReturnValue下符号断点,得到
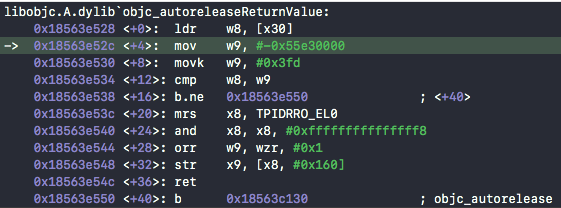
如果你输出x30寄存器的值(注意不是把寄存器的值当地址再取值)然后再减去所在二进制的基地址,会发现偏移正正好好也是0x62b0
而如果你加上之前提到的for循环代码,再断到obc_autoreleaseReturnValue去查看x30的值,计算偏移量会得到:0x0000000000005e98。
而对应到二进制里是:

看到没,这里调用objc_autoreleaseReturnValue走的是bl,也就是会修改LR寄存器,而LR寄存器的值就是调用后的返回地址5e98。而LR寄存器本身就是x30,导致autorelease的优化失效。
至此,我们终于发现了为什么我们的数据会被所谓的@autoreleasepool content持有。
后记
虽然正如网上很多文章所述,子线程确实会对autoreleasepool进行自动的管理避免内存泄漏。但是,由于诸多场景导致的释放时机变更,会产生诸多的内存不释放(并非是内存泄漏,Leaks是查不出来的),也会对App的稳定性造成巨大的影响。
更重要的是,基于这种TLS的优化很有可能被我们不知情下编写的代码所改变,产生奇怪的问题,因此要特别注意。
下文我会从编译以及代码生成的层面来探讨为什么会产生这种不同的汇编代码。